SpatialGPT
SpatialGPT
SpatialGPT
Building an AI Voice Assistant for XR!
Building an AI Voice Assistant for XR!
Building an AI Voice Assistant for XR!
SpatialGPT is a voice assistant designed for Apple Vision Pro, enabling seamless interactions in immersive environments. With intuitive voice commands, it simplifies how users navigate and engage with virtual spaces through voice user interfaces (VUI) for XR!
SpatialGPT is a voice assistant designed for Apple Vision Pro, enabling seamless interactions in immersive environments. With intuitive voice commands, it simplifies how users navigate and engage with virtual spaces through voice user interfaces (VUI) for XR!
SpatialGPT is a voice assistant designed for Apple Vision Pro, enabling seamless interactions in immersive environments. With intuitive voice commands, it simplifies how users navigate and engage with virtual spaces through voice user interfaces (VUI) for XR!
Goal
Designing & Developing VUIs for XR
Skills
SwiftUI Rapid Iteration VUI Design XR Design
Duration
1 month, Feb 2024
Role
Product Designer
My initial motivation for this project was to explore XR and the future of interfaces. However, as I designed and developed the assistant, it evolved into a learning journey where I not only built effective Voice User Interfaces (VUIs) across multiple platforms but also learned basic prototyping languages like SwiftUI and collaborated through pair programming with an AI agent.
My initial motivation for this project was to explore XR and the future of interfaces. However, as I designed and developed the assistant, it evolved into a learning journey where I not only built effective Voice User Interfaces (VUIs) across multiple platforms but also learned basic prototyping languages like SwiftUI and collaborated through pair programming with an AI agent.
My initial motivation for this project was to explore XR and the future of interfaces. However, as I designed and developed the assistant, it evolved into a learning journey where I not only built effective Voice User Interfaces (VUIs) across multiple platforms but also learned basic prototyping languages like SwiftUI and collaborated through pair programming with an AI agent.
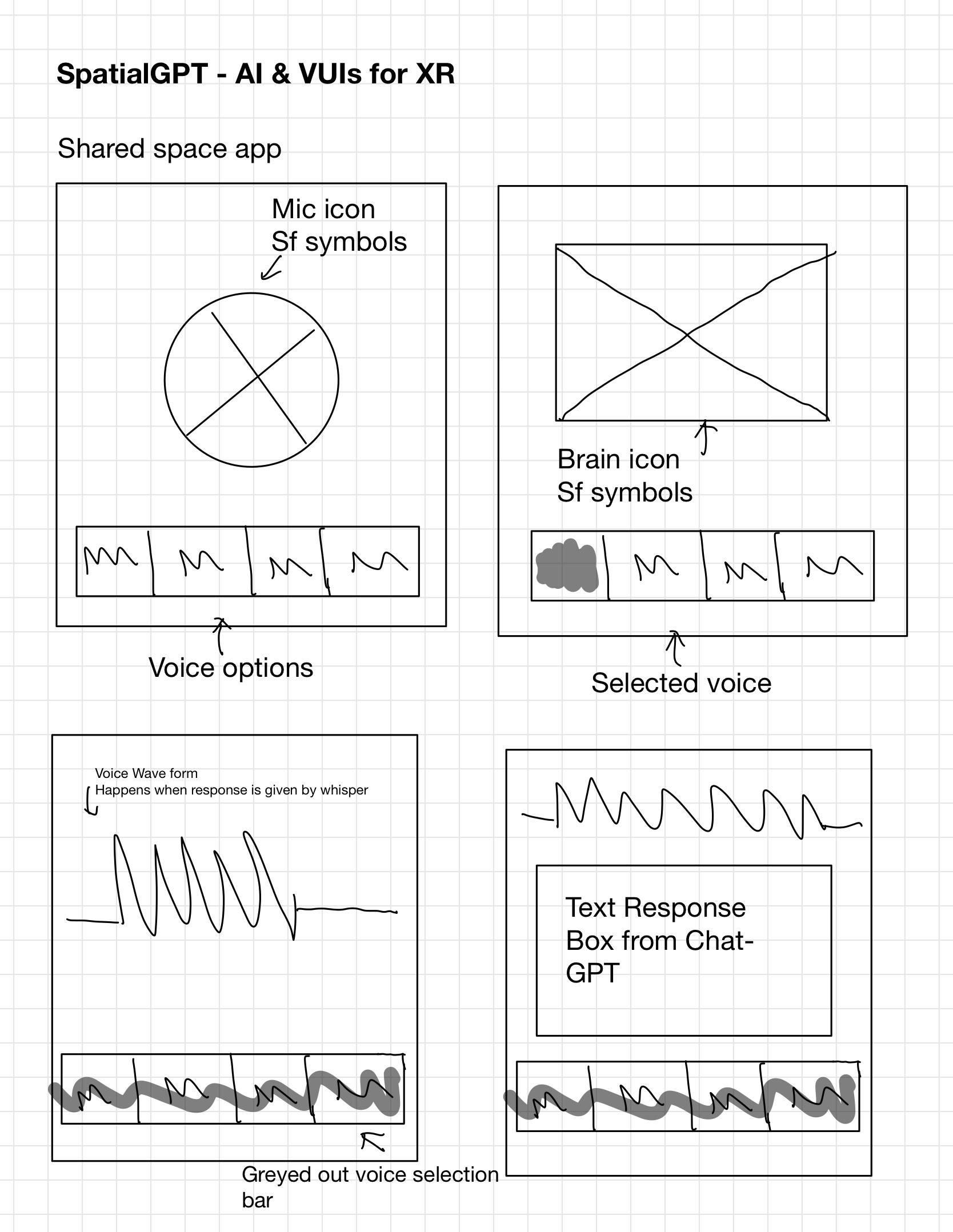

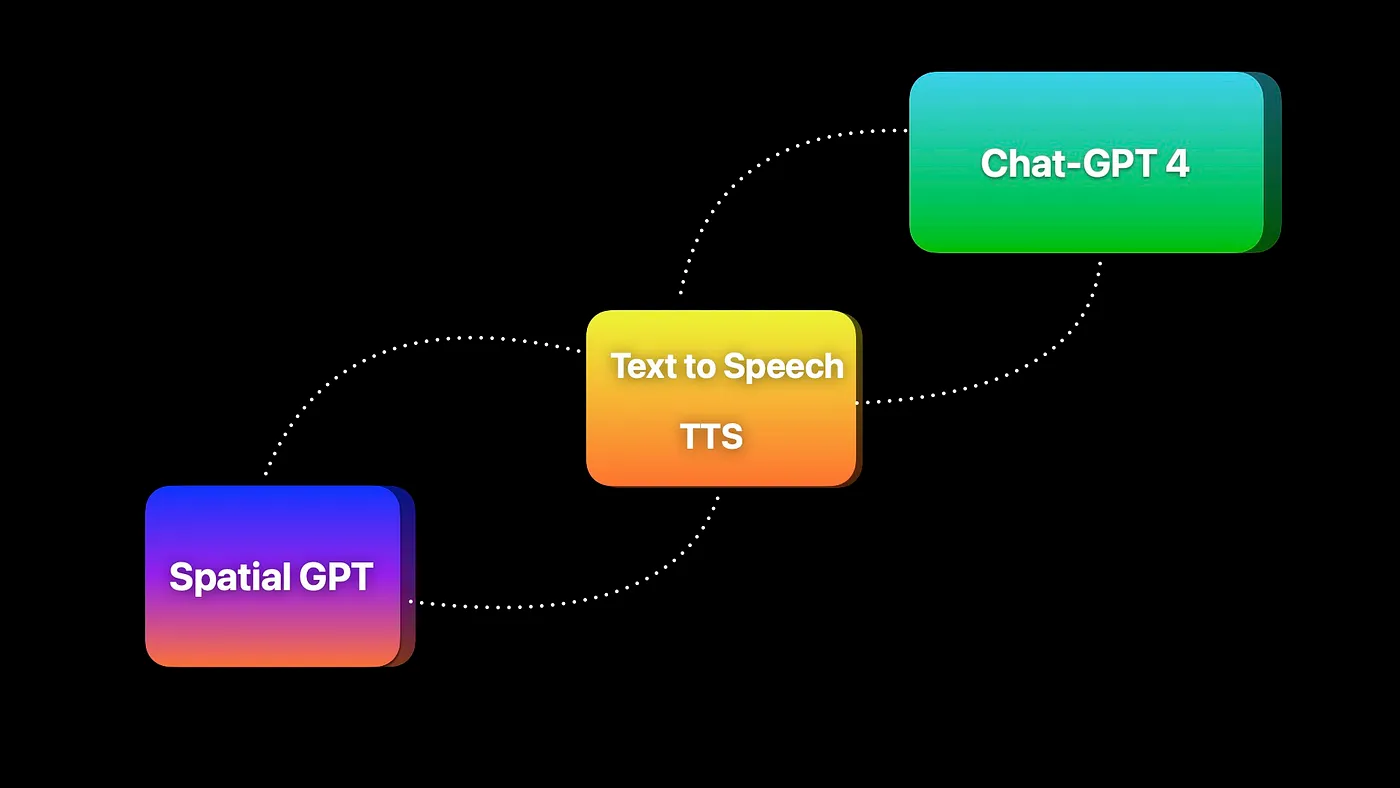
As this project explored multiple aspects in design and development of a Chat-GPT powered VUI - there are three main conclusions: 1.🥽 Designing for Spatial Context Designing for Vision Pro meant thinking beyond screens—voice interactions had to adapt to a 3D space. I focused on making the AI assistant context-aware, enabling seamless interactions for tasks like navigation or information overlays. 2. 🧠 Balancing Simplicity with Capability To reduce cognitive load, I prioritized short, natural responses and clear, minimal voice flows. The assistant was designed to offer help without being intrusive, stepping back when appropriate to keep the experience fluid and user-friendly. 3. ⚡️ 3. Designing for Real-Time Responsiveness Real-time feedback was crucial to make the assistant feel seamless and reliable. Any lag breaks immersion, so I focused on reducing latency and ensuring the assistant responded quickly and naturally—creating a fluid, uninterrupted interaction in spatial environments. Next Steps: 1. 🧪 Double User Testing: Increase testing sessions to identify edge cases and improve conversational flows. 2. 📝 Add Text Windows: Implement subtle text overlays for better visual feedback alongside voice interactions. 3. 👁️ Integrating Multi-Modality: Integrate basic visual input to improve context recognition in the user’s environment
As this project explored multiple aspects in design and development of a Chat-GPT powered VUI - there are three main conclusions: 1.🥽 Designing for Spatial Context Designing for Vision Pro meant thinking beyond screens—voice interactions had to adapt to a 3D space. I focused on making the AI assistant context-aware, enabling seamless interactions for tasks like navigation or information overlays. 2. 🧠 Balancing Simplicity with Capability To reduce cognitive load, I prioritized short, natural responses and clear, minimal voice flows. The assistant was designed to offer help without being intrusive, stepping back when appropriate to keep the experience fluid and user-friendly. 3. ⚡️ 3. Designing for Real-Time Responsiveness Real-time feedback was crucial to make the assistant feel seamless and reliable. Any lag breaks immersion, so I focused on reducing latency and ensuring the assistant responded quickly and naturally—creating a fluid, uninterrupted interaction in spatial environments. Next Steps: 1. 🧪 Double User Testing: Increase testing sessions to identify edge cases and improve conversational flows. 2. 📝 Add Text Windows: Implement subtle text overlays for better visual feedback alongside voice interactions. 3. 👁️ Integrating Multi-Modality: Integrate basic visual input to improve context recognition in the user’s environment
As this project explored multiple aspects in design and development of a Chat-GPT powered VUI - there are three main conclusions: 1.🥽 Designing for Spatial Context Designing for Vision Pro meant thinking beyond screens—voice interactions had to adapt to a 3D space. I focused on making the AI assistant context-aware, enabling seamless interactions for tasks like navigation or information overlays. 2. 🧠 Balancing Simplicity with Capability To reduce cognitive load, I prioritized short, natural responses and clear, minimal voice flows. The assistant was designed to offer help without being intrusive, stepping back when appropriate to keep the experience fluid and user-friendly. 3. ⚡️ 3. Designing for Real-Time Responsiveness Real-time feedback was crucial to make the assistant feel seamless and reliable. Any lag breaks immersion, so I focused on reducing latency and ensuring the assistant responded quickly and naturally—creating a fluid, uninterrupted interaction in spatial environments. Next Steps: 1. 🧪 Double User Testing: Increase testing sessions to identify edge cases and improve conversational flows. 2. 📝 Add Text Windows: Implement subtle text overlays for better visual feedback alongside voice interactions. 3. 👁️ Integrating Multi-Modality: Integrate basic visual input to improve context recognition in the user’s environment